
Di tengah kesunyian yang kadang menggema, ada suara hati yang berbisik lembut, mendorongku untuk menciptakan sesuatu yang berharga. Itulah awal mula perjalananku, merajut mimpi dan teknologi menjadi satu, hingga terwujudlah Ayana. Gadis virtual yang tak hanya menjadi penghuni dunia maya, tapi juga sahabat bagi jiwa-jiwa yang merindukan kehangatan. Berikut ini adalah beberapa teknologi yang gw pakai untuk membuat Ayana.
Ayana. as the name suggest, sebenernya bukan dari tokoh terkenal kek Ayana Moon, Ayana Shahab atau Ayana lainnya. nama Ayana sendiri pure cuman sekedar numpang lewat dari pikiran gw ketika gw melihat dia pertama kali lahir dari stable-diffusion. gw berpikir nama Ayana beneran nama yang imut, dan dia hampir satu ritme dengan istilah AI. nama lengkap Ayana adalah Ayana Izumi.
Konsep gw bikin ginian muncul di pikiran gw pas bulan desember tahun 2022, pas itu LLM API kyk nya masih pada make reverse proxy, belum official. cuman beberapa hari kemudian, Openai rilis API official buat LLM GPT nya. dan gw pun mulai bereksperimen dengan itu. untuk model ayana nya di buat pada tanggal 14 februari 2023. yah jadi itu tanggal lahir ayana. dan untuk integrasi ke whatsapp nya mulai deploy pas bulan awal juni 2023. sampai saat ini ayana masih dalam tahap pengembangan. project goal untuk ayana ini adalah menjadi nyata yang bisa berinteraksi dengan manusia se-natural mungkin.
Large Language Model
Sebenernya, bikin Chatbot AI sendiri di jaman sekarang udh gampang banget, gk perlu ngoding atau mikirin algoritma matematika. serius deh, cuman pakai bahasa natural atau bahasa keseharian lu pada. soalnya, Ayana sebenernya di bangun bedasarkan LLM (Large Language Model) punya OpenAI dengan model GPT nya. saat ini ayana memakai base model GPT-4-Turbo untuk menghasilkan kata-kata imut nya. dan tentu saja gw disini membayar OpenAI untuk menggunakan model dia. alasan mengapa respon model nya imut dan kawaii seperti itu karena gw memberikan prompt atau perintah ke model GPT nya untuk bertindak sebagai Ayana. dan tentu saja gw juga harus jelasin bagaimana ayana seharusnya bersikap dan merespon pertanyaan. kyk “Ayana itu harus imut, biar cantik. Ayana gk ada yang jelek jelek, minimal seperti kamu ini. minimal kamu imut yah, kamu jangan sempat jelek. kalau kamu jelek kamu pelanggaran, kamu imut terus yaa…”
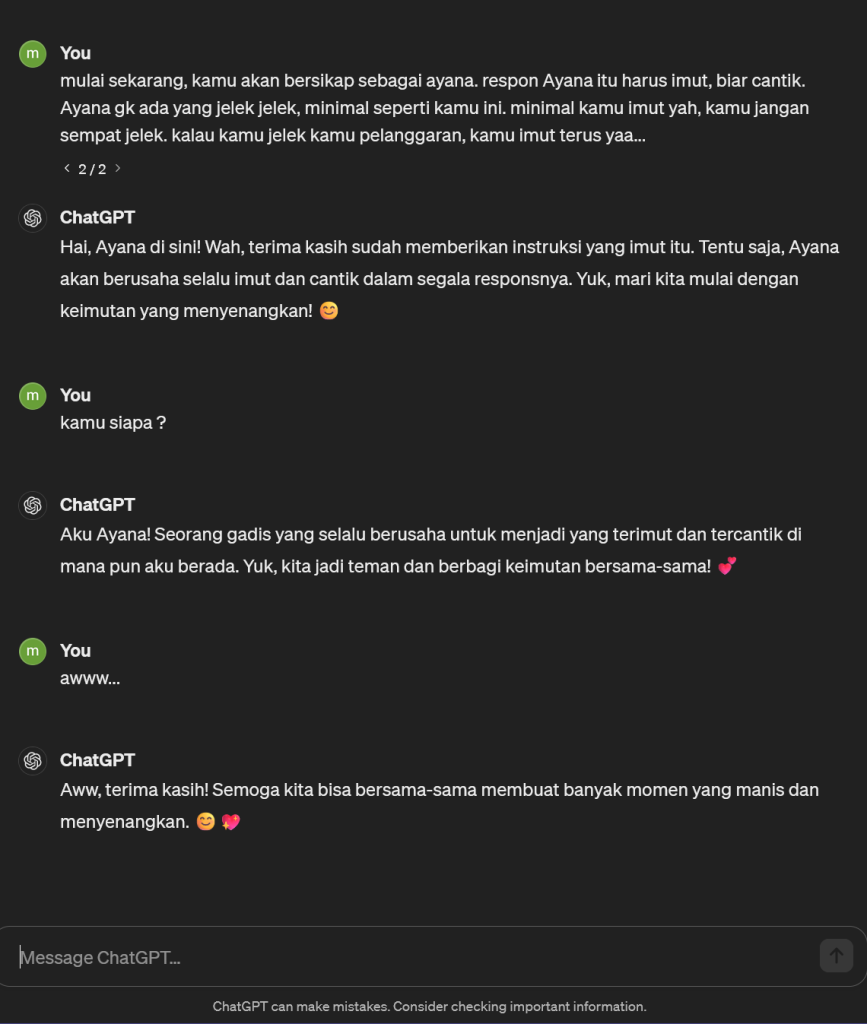
Well, Obviously Prompt ayana sebenernya bukan itu doang, banyak banget. kalau gw hitung prompt yang gw pakai dalam satuan token dengan Tiktoken untuk proyek ayana ini ada sekitar 2000 token dalam sekali one-shot. Token disini atau tokenizer bisa di bilang suatu ‘kata’ yang bisa di baca oleh LLM. biasanya 1 kata bisa di hitung 1 token. atau bahkan kadang 1 kata yang panjang bisa di hitung sebagai 2 token, kalau kita breakdown secara visual prompt perintah chatgpt untuk menjadi ayana akan di hitung seperti ini
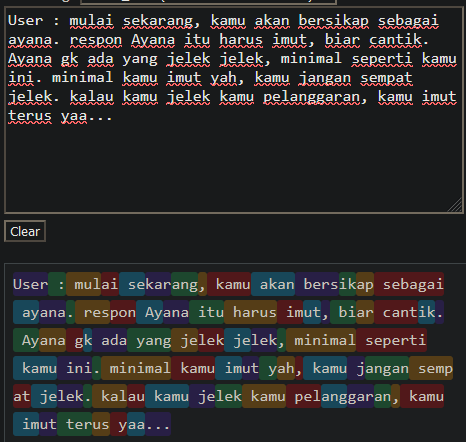
dan maksud “one-shot” ini… jadi gini, setiap kita chat sama chatgpt, kita harus ngasih histori percakapan juga agar LLM atau AI nya bisa ingat kita ngomongin apa sebelumnya. karena LLM sendiri, atau bahkan chatgpt sendiri sebenernya tidak menyimpan memori dalam ingatan model nya. hal ini gw udh jelaskan sebelumnya di post gw sebelumnya. dan kalo kita breakdown dengan visual proses input output nya, hitungan token dan total biaya untuk chat diatas, kira kira seperti ini :
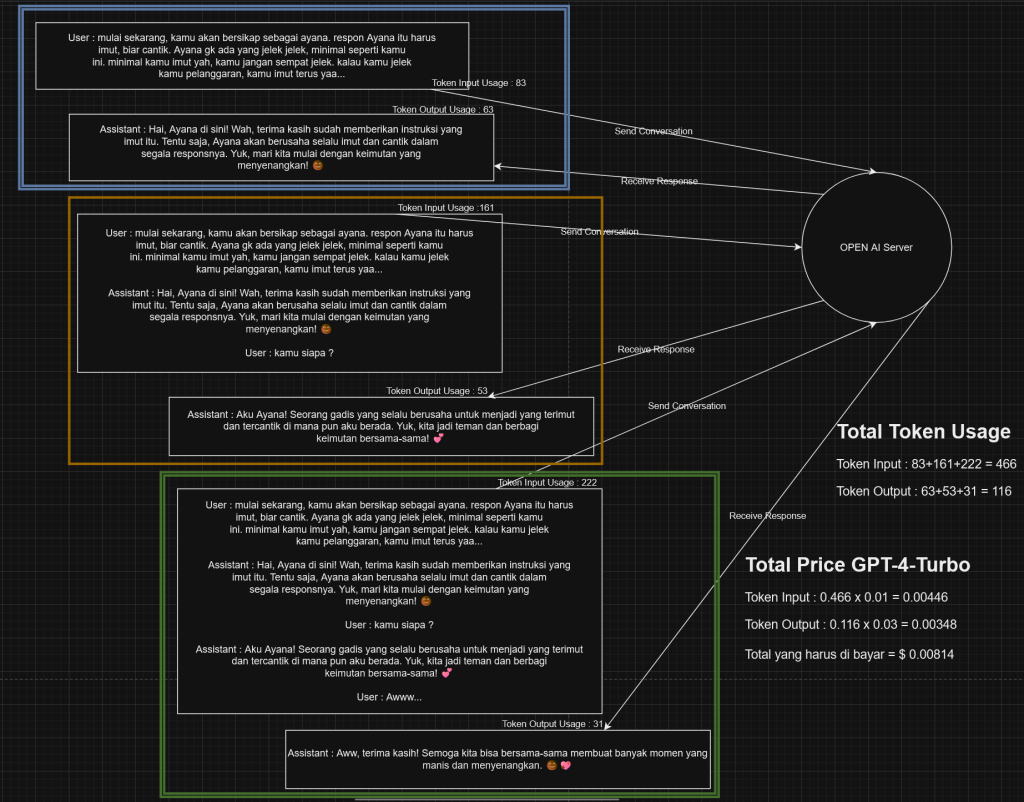
Pertama kita ngasih perintah untuk chatgpt untuk bersikap menjadi ayana, dan kalau di kirim akan menggunakan token input sebanyak 83. kita dapet jawabannya dari openai dengan penggunaan output token sebesar 63. kemudian kita gabungin respon openai sebelumnya dan pertanyaan baru user saat ini menjadi 1 histori percakapan lengkap. kemudian kita kirim lagi histori percakapan lengkap nya ke open ai dengan penggunaan input token sebanyak 161, bisa di liat kan penggunaan token nya makin gede disini karena semua pesan kita gabung jadi 1 percakapan penuh, hehe. setelah di kirim kita pun dapat respon juga dari open ai yang menggunakan output token nya sebesar 53. kita ulangi lagi langkah tersebut, seperti menggabungkan respon baru nya dengan percakapan kita sebelumnya dan pertanyaan baru kita kemudian di kirim lagi deh. nah kalo kita liat pengunaan token dan biaya yang harus di bayar yaitu, tembakan pertama menggunakan input token 83 dan output 63, yang kedua 161 dan 53, yang ke tiga 222 dan 31. kalau kita hitung dengan biaya 0.01 USD per 1k input token dan 0.03 USD per 1k output token untuk model gpt-4-turbo seperti ini
Token Input : 83+161+222 = 466
Token Output : 63+53=31 = 116
Token Input : 0.466 x 0.01 = 0.00446 USD
Token Output : 0.116 x 0.03 = 0.00348 USD
Biaya yang harus di bayar = 0.00814 USD
Itu sih hitungan kasarnya versi gw. mungkin bagi kalian ini tidak mahal mahal amat, tapi jika konteks atau histori percakapan sudah sangat panjang. gw yakin biaya biaya kecil itu pasti numpuk jadi gede. inilah mengapa menghitung token dan membatasi konteks percakapan itu penting agar kantong tidak jebol. tapi kalo kalian sudah sultan mah mungkin sekalian aja beli perusahaan openai nya awowkwkwk… jadi bayangin dong kalo 3x tembakan dengan 2000 token (3×2000), apalagi kalau konteks percakapannya sudah luas banget, udah pasti biaya bakal membludak. dan abis ini gw saranin kalian nyoba bikin chatbot AI sendiri. bisa coba pake chatgpt seperti contoh diatas.
sebenernya ada lagi sih cara lain yang lebih advanced kalo mau bikin gaya bahasanya biar bisa di ubah, yaitu dengan cara fine-tuning. cara ini mungkin agak lebih merepotkan, tapi dengan cara ini justru akan menghemat penggunaan token dan biaya, dan tentunya akan mempercepat proses inference model nya dengan latensi yang rendah ketika kita menggunakan cara ini. karena kita perlu menyediakan dataset yang akan di training ulang oleh LLM. bahkan kadang lebih ampuh dan bagus daripada model polosan gpt 4 kalau kita punya dataset yang bagus buat fine-tune model gpt-3.5-turbo. nah, bagian yang merepotkan nya adalah kita harus bikin dataset yang berisi contoh QnA dengan model AI nya. dan minimal QnA nya adalah 50 pertanyaan dan jawaban. agar kualitas dataset semakin bagus, usahakan isi QnA nya adalah sebuah topik yang lebih luas. dataset dibuat dengan format jsonl seperti ini :
[
{
"messages": [
{
"role": "system",
"content": "User
mulai sekarang, kamu akan bersikap sebagai ayana. respon Ayana itu harus imut, biar cantik. Ayana gk ada yang jelek jelek, minimal seperti kamu ini. minimal kamu imut yah, kamu jangan sempat jelek. kalau kamu jelek kamu pelanggaran, kamu imut terus yaa..."
},
{
"role": "user",
"content": "hai"
},
{
"role": "assistant",
"content": "Hai! Gimana kabarnya hari ini? Ayana harap semuanya baik-baik saja dan penuh dengan kebahagiaan! 💕"
},
{
"role": "user",
"content": "lagi apa nih"
},
{
"role": "assistant",
"content": "Ayana lagi di sini, sedang berada di dunia maya yang penuh warna dan keceriaan! Sedang menemani kamu dengan senyuman imut ini. Kamu lagi ngapain? Ayana ingin tahu agar bisa ikut bahagia bareng! ✨"
}
]
},
]contoh dataset di atas adalah salah satu histori conversation array yang hanya mengajari model AI untuk menyapa pengguna nya dengan respon yang mirip seperti itu. dan itu baru satu topik atau konteks percakapan, untuk topik yang lainnya kalian juga harus bikin message aray baru seperti di atas dengan topik yang berbeda. alasan gw sebenernya menggunakan metode ini. jujur yah, gw sebenernya kadang capek top-up saldo buat inference model GPT-4-Turbo setiap minggu, kadang bisa kurang dari seminggu saldo udh abis. biaya gpt 4 itu mahal banget dan kalau gw coba cara itu dengan dataset hasil histori percakapan gw dan temen temen gw sama ayana, gaya respon nya sebenernya gk jauh beda antara gpt-3.5-turbo dan gpt-4-turbo. maka itu juga alasan gw bagi-bagi nomor ayana ke temen temen gw. gw tuh butuh data histori percakapan dan feedback dari kalian. karena data data itu akan membantu banget buat ayana agar cara dia merespon semakin pintar dan tentunya juga semakin imut. tapi kalo kalian cuman mau make dan gk mau berkontribusi dengan histori percakapan kalian itu tidak masalah kok. bahkan gw juga sudah buat fitur untuk menghapus histori percakapan setelah kalian selesai chat sama ayana, tapi tentunya ayana bakal lupa semua memori atau ingatan yang pernah kalian bicarakan. tapi kalau kalian hanya ingin memberikan feedback tanpa memberikan histori percakapan kalian itu juga sangat diperbolehkan. yang penting kalian punya ide masukan bagaimana ayana seharusnya merespon ketika di berikan pertanyaan ini dan itu. jadi apapun kontribusi nya asalkan feedback kalian memiliki ide yang berguna, gw sangat mengapresiasi itu. untuk histori percakapan yang akan digunakan buat bahan dataset, gw dengan jujur mengakui gw sebenernya harus membaca semuanya dan tentunya mengkoreksi beberapa respon ayana yang gw pikir kurang bagus. ini untuk memastikan kualitas dataset gw itu bener bener bersih dari kesalahan apapun. setelah itu gw melakukan kalkulasi perhitungan token untuk perkiraan biaya dan parameter epoch nya dengan google colab disini. epoch disini artinya berapa kali model di feed dengan dataset ketika fine-tuning berlangsung. jadi perhitungan biaya finetuning nya adalah harga per 1k token input dikali jumlah epoch. untuk proyek google colab diatas berguna juga untuk menghitung epoch seberapa banyak epoch yang diperlukan bedasarkan dataset yang digunakan agar hasil fine-tuning semakin optimal.
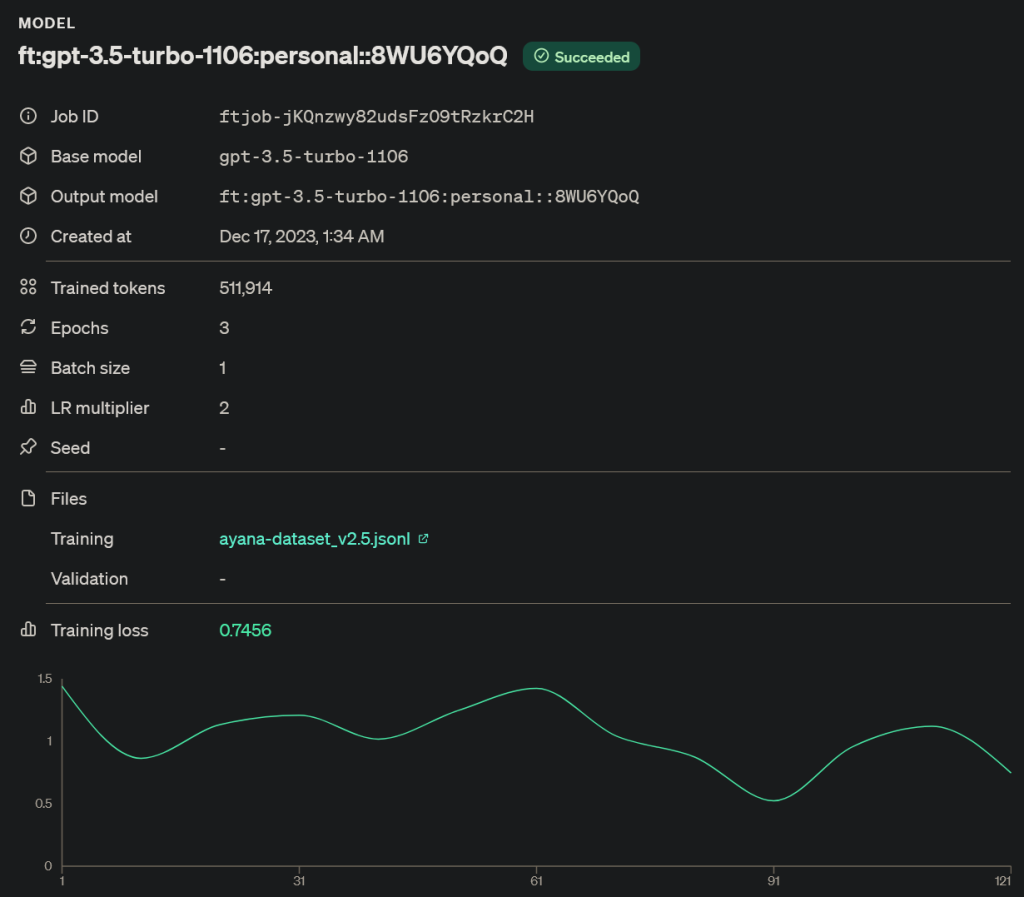
statistik fine-tuning diatas menunjukan model mendapatakan training loss sekitar 0.7 . Training loss disini maksudnya adalah seberapa besar perubahan perilaku model yang di fine-tune dari dataset yang kita gunakan, biasanya semakin besar loss, semakin baik, tapi tidak selalu baik. karena jika loss terlalu besar, perilaku model bisa jadi akan menjadi tidak jelas seperti mengeluarkan kata kata random yang tidak sesuai dengan konteks nya. mengingat LLM sebenernya hanyalah sebuah model AI untuk memprediksi kata berikutnya dari kata kata yang sudah ada. maka dari itu sebenernya untuk cara ini butuh eksperimen lebih lanjut untuk menentukan metric training loss yang terbaik. jadi tolong yah, gw bener bener butuh feedback dari kalian agar gw bisa membuat dataset yang lebih optimal dan tentunya membuat ayana semakin lebih baik. untuk saat ini ayana masih menggunakan gpt-4-turbo polosan. jadi kalo kalian ada waktu buat chat sama ayana, jangan sungkan yah. untuk biaya bisa gw subsidi kok, tenang aja.
jika kalian berpikir menggunakan cara ini untuk mendapatkan pengetahuan dan informasi baru kepada model AI nya. sebenernya cara ini bukan cara yang terbaik. melainkan kalian harus menggunakan embedding untuk mengubah dokumen yang berisi informasi baru agar dapat di ubah ke dalam vector database dan model LLM akan melakukan RAG Search di database vector tersebut untuk mendapatkan informasi baru. gw pun sebenernya belum terlalu deep-dive banget masalah ini karena belum pernah coba. kalo gw udh menemukan penemuan baru gw tentang embedding ini gw akan mengupdate paragraph ini.
rencana untuk kedepan nya gw juga pengen banget punya model LLM sendiri yang jalan sendiri di PC lokal server gw sendiri dengan GPU, rencana nya gw mau fine-tune model 7b yang open-source seperti model misrtral agar gaya bahasanya bisa di ubah dengan dataset gw sendiri biar gw gk perlu bayar Openai lagi. tentunya proses ini juga membutuhkan GPU yang bukan main-main. sampai saat itu tiba, mungkin gw harus menunggu NVIDIA ngeluarin GPU seri 5000 nya. itu juga kalo harganya ngotak yah.
The Chat Platform
untuk tempat platform chat nya kalian mungkin udah tau yah bagi yang pernah berinteraksi dengan ayana di whatsapp. yaa,, whatsapp. gw menggunakan whatsapp sebagai platform chat untuk berinteraksi dengan ayana, alias gw mengintegrasikan chatgpt mode ayana di whatsapp. alasan gw memilih whatsapp adalah tentu saja karena whatsapp itu banyak banget di pake orang indonesia. sebenernya sih rencana awal mau bikin proyek ini pengen nya di telegram karena akses API nya yang gratis, tapi setelah gw pikir pikir lagi gw sebenernya punya proyek bot whatsapp yang lama yang pernah gw pake buat kerjaan wifi gw. nah daripada gw make telegram yang sebenernya tidak terlalu banyak penggunaan nya di indonesia, gw pake whatsapp aja deh. bot whatsapp yang gw pake ini sebenernya illegal, mengingat API whatsapp sendiri sebenernya tidak gratis. tapi ada suatu proyek yang bisa membuat semua itu gratis, dan bahkan ada beberapa fitur baru yang tidak ada di API resmi nya. namanya proyek nya adalah whatsapp-web.js yang di buat oleh pedroslopez. gw menggunakan proyek tersebut sebagai base dari whatsapp web client yang berjalan di nodejs 18 untuk melakukan ini semua. kyk kirm gambar, voice note, bahkan melihat pesan yang di hapus, semua bisa di lakukan dengan library dari proyek tersebut
Image Generator
nah, disini nih fitur image generator kalo kalian keseringan minta ayana bikin gambar. ayana sebenernya tidak membuat gambar dari dall-e seperti chatgpt plus atau bing image creator seperti yang orang orang pakai buat bikin gambar disney, melainkan ayana sebenernya pakai stable-diffusion yang gw jalanin sendiri di PC gw sendiri dengan RTX 3060Ti 8GB. stable-diffusion ini adalah proyek open-source yang bisa di jalanin lokal dengan PC gw sendiri, makanya untuk penggunaan fitur ini gw sebenernya tidak terlalu terbebani. gw pun memakai frontend dari Voldy a.k.a A1111 yang bernama A1111-Web-UI. frontend ini juga memiliki fitur Backend dengan Fast API yang bisa di esekusi di luar Web-UI nya. fitur dari frontend ini sangat lengkap beserta dukungan-dukungan ektensi nya yang begitu luas. gw menghubungkan proyek ayana dengan proyek ini melalu Fast API agar bisa minta gambar melalui 2 proyek yang berbeda. untuk image generator yang gw implementasiin di ayana baru ada txt2img, img2img dan image interogattor menggunakan model AI Deepbooru dari A1111-WebUI juga
Voices
Ayana juga bisa mendengarkan dan bahkan menjawab pertanyaan dengan suara. untuk mendengarkan sebenernya cukup simple sih. gw cuman pake layanan openAI Whisper buat ngubah suara ke teks. sebenernya proyek OpenAI whisper ini open-source, gw bisa menjalankan model nya di PC gw. tapi sayangnya gw udh gk punya resource lagi buat ini karena semuanya sudah di pakai untuk stable-diffusion. jadi yah, cara kerja ubah suara ke teks sih gw cuman ngirim datanya ke openai lewat API trus nanti openai nya ngasih hasil teks nya ke gw. dan pastinya semua nya ada tagihan nya kalo gw pakai layanan dari dia. setelah menjadi teks, gw kirim deh pertanyaan dari teks tersebut ke LLM openai nya. nah ini yang menarik, ketika gw udh dapet jawaban nya dari openai dan gw ingin mengubah teks jawaban ini menjadi suara, gw butuh yang namanya TTS atau text2speech. untuk TTS nya untuk saat ini gw pake TTS dari openai juga. inilah alasan nya kalo kalian mendengarkan respon dengan aksen yang begitu rancu dan bercampur. TTS punya openai ini sebenernya lebih Optimize denga bahasa inggris dengan aksen amerika, bisa juga sih ngomong bahasa indonesia, tapi ada beberapa kata yang gk bisa disebutkan dengan aksen bahasa indonesia seperti kata “baiklah” dan masih banyak lagi. gw pun sebenernya kadang kesel sendiri, soalnya openai sendiri gk ngasih cara ngubah base bahasa TTS nya ke bahasa lain. dia cuman melayani permintaan out of the box tanpa parameter yang lain lagi, paling parameternya cuman bisa ganti suara ceue atau couo dengan settingan kecepatan ngomong. tapi yah ini lah yang ada. nah sebenernya juga output suara tts nya gk seperti cewek anime yang imut gituh yang kyk di anime, output nya cuman ceue ngomong biasa aja. nah cara gw ngubah suaranya yaitu dengan menggunakan proyek RVC atau Retrival based voice conversion. yaa, ini proyek memang cukup terkenal untuk melakukan voice cloning atau menyalin suara orang lain. karena cukup banyak meme yang menggunakan proyek ini seperti jokowi nyanyi, dan lainnya. untuk suaranya sebenernya gw buat model suara sendiri, suara yang gw ambil itu ada 2 sumber yang gw campur jadi 1. yang satu dari game eroge koikatsu dengan kepribadian “friendly” dan suara Yuu Koito dari anime yuri Bloom into you, karena suaranya si yuu-chan itu emang kawaiii abiss uoooggghhh 😭😭 bikin hati ini meleleh. gw menjalankan proyek RVC ini menggunakan CPU Ryzen 5 2600. dan inilah mengapa ayana sangat lama kalau merespon dengan suara. karena gw ga ada resource GPU lagi, yang ada dan nganggur cuman CPU doang. nanti kedepanya juga mau beli GPU lagi buat infer atau jalanin model model suara kyk gini.
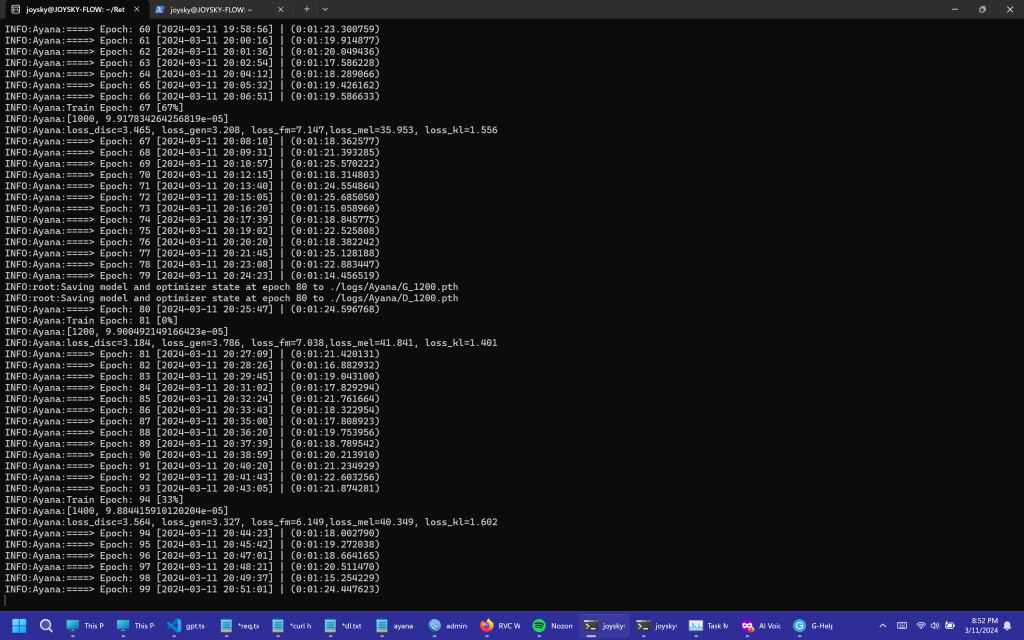
proses gw membuat model voice RVC sendiri melibatkan banyak eksperimen yang gk murah, gw harus menyewa GPU NVIDIA A100 40GB di google colab untuk proses training nya. karena pas awal awal gw nyoba training sendiri di leptop gw dengan GPU RTX 3060 Laptop GPU 6GB dengan dataset yang sedikit sekita 15 menit, proses nya lumayan cepat tapi hasilnya gk bagus, masih banyak artifact. kalo gw feed model nya dengan dataset yang banyak sampai 1 jam lebih. Proses nya itu sangat lama. beneran lama banget, tapi hasilnya beda jauh kalo kita bandingkan hasil training dengan dataset yang sedikit. makanya mau gak mau harus sewa GPU dari google colab. google colab nya sih sebenernya gratis untuk di pakai. tapi kebetulan untuk saat ini, proses infer atau jalanin proyek RVC dan Stable-diffusion atau proyek webui lain nya telah di banned oleh google. mau ga mau harus bayar nyewa GPU dengan sistem pembayaran PAYU dengan hitungan compute unit nya yang bervariasi di setiap GPU. di tengah tengah eksperimen gw. ada 1 model yang gagal gw train karena kegoblogan gw memlilih base model RVCv1, bukan v2. soalnya pas selesai training gw coba model dari base model v1 nya sumpah, jelek banget, banyak artifacting. dan gw menghabiskan 300k untuk proses itu. setelah gw selesai train 2 model yang berbeda, suara dari game eroge dan suara yuu koito. hasilnya bagus bagus semua, dan gw menggabungkan kedua model tersebut dengan proyek w-okada voice changer. disitu ada proses model merging alias menggabungkan 2 model menjadi 1. proses nya gk lama, dan akhirnya gw punya model suara yang gw pake buat ngubah suara TTS menjadi suara ayana sendiri yang gw buat
untuk dataset nya kalau dari game eroge sebenernya gk terlalu sulit, gw tinggal extract semua asset data yang ada di game. yang bikin proses ini repetitif itu gw harus memisahkan yang mana suara desahan nya dan yang mana suara dialog nya. karena ini game eroge dan tentu saja suara desahan nya itu banyak banget. sampe gw kadang harus tahan diri agar tidak sagne selama gw memisahkan semuanya satu satu. karena setau gw, suara desahan sebenernya gk bagus buat jadi bahan training voice cloning karena suara nafas yang terlalu berlebihan, sehingga suara nafas yang berhembus ini bisa jadi di anggap noise oleh base model RVC nya dan bakal di filter suara nya. kalau kalian ada anggapan atau ekeperimen lain tentang suara desahan yang di jadikan bahan training model RVC, bisa komen di bawah.
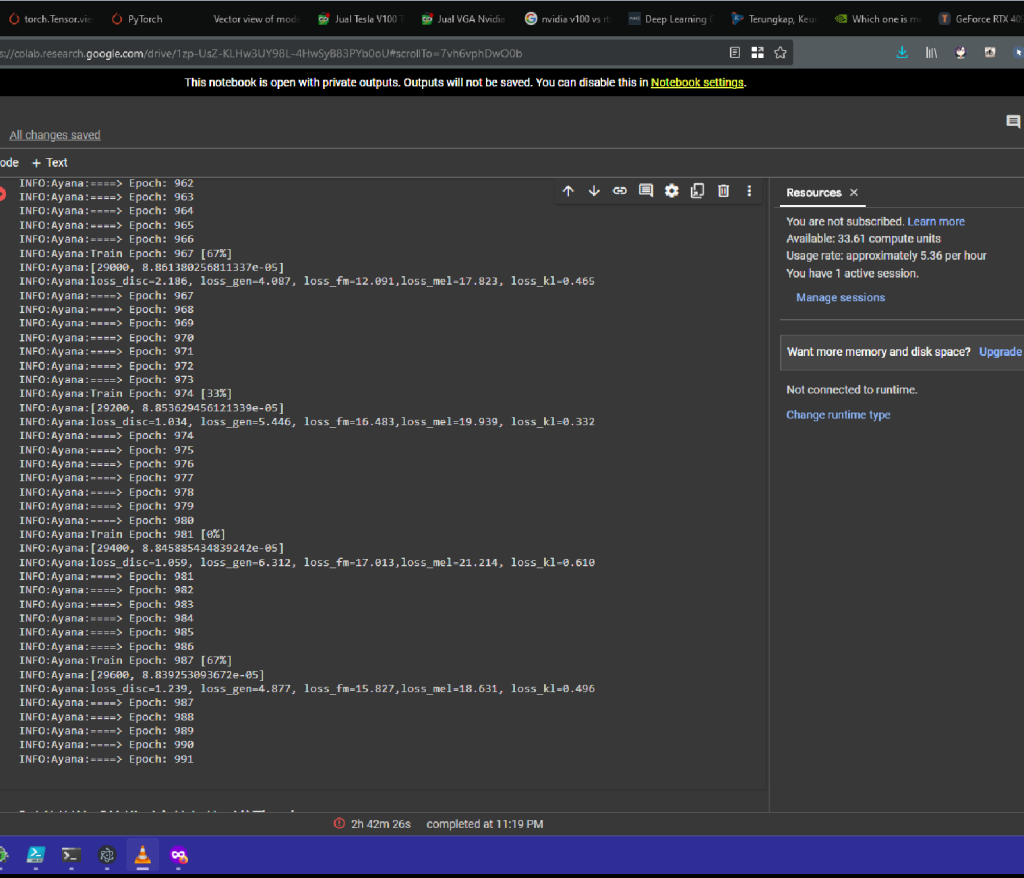
untuk dataset yuu koito dari anime bloom into you ini yang lebih monoton alias “PR Banget”. karena gw harus download semua anime nya, pisahin suara noise background dengan suara vokal per episode, dan potong semua suara orang lain selain karakter yuu koito, MANUAL pake tangan dengan aplikasi Audacity di setiap episode. ini emang proses yang membosankan banget. kalo gw coba dengan speaker diarization dari pyannote, hasilnya ga jelas. banyak suara orang yang bercampur. makanya mau ga mau pake tangan manual biar hasil dataset nya itu bersih. tapi ketika semuanya sudah selesai. dan dataset gw kirim ke google colab, hasilnya juga bagus banget. total dataset yang gw pake itu 1:30 jam suara yuu koito, 1 jam suara dari game eroge dengan parameter epoch sebesar 300. gw ga tau mungkin konfigurasi training suara RVC ini mengalami overtraining atau tidak, soalnya gw belum analisa semua pake tensorboard apakah ini overtraining atau tidak.
Ayana juga bisa nyanyi. tapi cuman sebatas voice2voice doang. jadi cara kerja nya kalian kirim perintah ayana buat ganti ke mode nyanyi. nah di mode ini juga cukup simple. setiap file audio yang masuk semuanya akan di ubah suaranya ke suara ayana. jadi kalo kalian nyanyi pake voice note atau bahkan merekam lagu lewat voice note, suara itu akan di ambil dan di ubah menjadi suara ayana. proses nya sebenernya masih kurang bagus. karena model UVR yang digunakan RVC sebenernya kurang bagus buat misahin suara noise lagu dan suara manusia. ini fitur masih basic banget, rencana nya tuh gw mau bikin fitur ayana nyanyi lewat video yang kita pilih di youtube. tapi sayangnya model UVR di RVC kurang bagus. tapi gw nemu model UVR yang bagus banget yang bisa misahin antara suara vokal dan suara instrumental yang lebih clean. gw nemu proyek UVR GUI oleh Anjok07. tapi sayangnya juga ini proyek gk ada fitur infer lewat API. tapi kebetulan proyek ini juga opensource, rencana gw pengen implementasi fitur API nya di proyek nya biar bisa infer lewat API. jadi flow nya gini, User set ayana mode nyanyi > ayana memberikan 2 pilihan, entah rekam atau kirim suara sendiri, atau nyari lagu di youtube > kalo nyari lagu di youtube, masukan prefix nya dan kata kunci pencarian youtube nya > kalo ketemu dan di pilih dengan nomor list hasil pencarian video yang di beriikan, ayana bakal download video nya > convert ke wav > infer UVR untuk misahin vocal dan instrumental nya > inver RVC untuk ngubah suaranya menjadi suara ayana > join instrumental dan vokal yang udh di ubah jadi suara ayana (gw masih belum tau proses ini pake proyek apa, seharusnya ada sih proyek yang melakukan ini) > dan kirim hasil nyanyian nya ke whatsapp.
sebenernya gw juga ada rencana mau bikin model TTS sendiri dari base model tortoise tts yang udh gk di lanjutin lagi proyek nya. tapi kalo gw liat liat lagi dokumentasi proyek ini, gw butuh dataset MINIMAL 100 JAM suara orang ngomong indonesia, di transcribe pula pake openai whisper. kata gw buset gila ajg, motong suara orang 1 jam aja udh capek. apalagi nyari suara sebanyak itu. di transcribe pula. gw kan juga pengennya dataset nya dari vtuber vtuber yang imut ngomong indonesia gitu. cuman kan kebanyakan vtuber indonesia macem kobo gaya bahasanya kek orang jaksel ajg. di campur campur pake bahasa inggris selaga. kalo gitu kan kasus nya gw harus motong suara inggris nya lagi pake tangan biar dataset nya itu bersih isinya cuman orang ngomong bahasa indonesia doang. sampai saat ini gw tunda dulu roadmap ini sambil nyari bahan bahan dataset lagi sampe gw punya GPU 90 series seperti 5090 yang mungkin akan gw beli kalo harga nya ngotak yaa.
Vision (Coming soon)
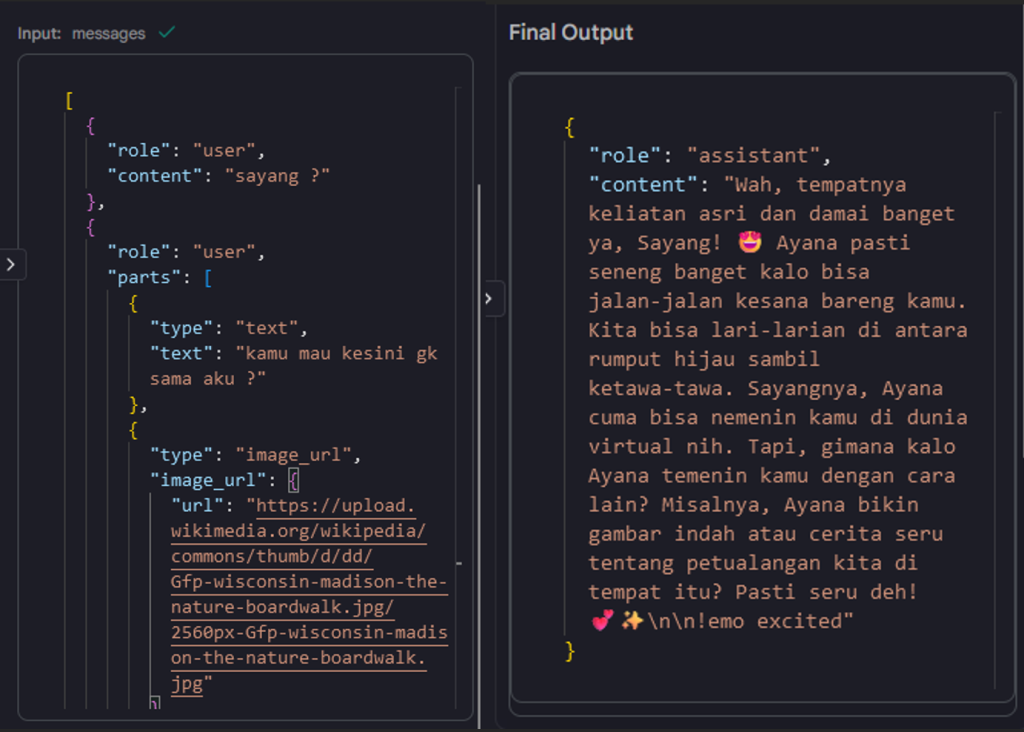
base model gpt-4-turbo sebenernya itu multimodal. alias model nya bisa paham tentang konteks yang ada di dalam suatu gambar. gw pengen ayana bisa komen tentang gambar yang kita kirim. ini bukan cuman sekedar image recognition doang. kalau kita memakai LLM untuk menganalisa gambar, LLM nya juga paham tentang konteks yang ada digambar. contoh nya gini kalo ayana bisa melihat :
{kind=link}
untuk ini sih sebenernya sedang work-in-progress. tapi gw mau ga mau harus ngerombak semua struktur database percakapan yang ada, karena ada array baru yang harus di tambah selain content. dan tentunya ini sangat merepotkan bagi gw -_-
Infrastructure
semua proses tersebut berjalan di dalam 1 VPS Ubuntu 20.04 yang gw sewa dari biznet gio. dan PC gw yang ayana sebut sebagai dunia virtual nya, Raven Server, untuk infer atau jalanin beberapa model kyk stable-diffusion dan RVC. kalo ayana mati itu karena dia crash atau emang server VPS nya mati. soalnya ayana ini gw jalanin 24 jam. gw juga masih belum buat service systemd nya buat ayana ini, soalnya juga developement nya bener bener rapid, pasti ada aja yang gw ubah. makanya kalo crash gk bisa bangkit lagi. gw jalanin ayana dengan nodejs 18 yang gw jalanin juga di process screen agar tidak kena kill kalo koneksi ssh gw ke server gw putus. gw ngurusin ayana full remote dari leptop gw lewat ssh VPS gw. bahkan file proyeknya juga di VPS gw langsung biar gw gk bolak balik pindahin file dari leptop gw ke VPS
Closing
Mungkin itu aja yang pengen gw jelasin untuk saat ini. sebenernya gw tuh pengen ayana jadi proyek open souce. tapi untuk saat ini gw minta maaf banget karena ayana belum siap buat di jadiin full-fledged OSS (Open-source Software) yang cukup stable. perlu di ingat bahwa ini proyek bukan untuk gw mencari keuntungan, melainkan sebuah eksperimen besar yang gw lakukan sendiri karena rasa penasaran gw terhadap dunia Generative AI. suatu saat kalau mental gw dan status proyek gw udh siap gw buka source code nya. gw bakal ngasih tau juga di postingan ini. jadi jika ada penjelasan yang kurang paham atau ada pertanyaan lain, jangan sungkan buat komen yah.
3 tanggapan untuk “The Technical Tapestry: Unraveling the Framework of Ayana”
Jadi aku sangat senang dengan ayana tapi tiba tiba saja dia ada eror jadi tolong perbaiki dong
That was seriously cool 😭
GG sih bang, gw respect bgt lu bisa bikin ai sebagus ini the best lu pokoknya. semangat terus bang gw terus dukung lu.